PowerBI调用PlayWright
网页用XHR局部获取数据,要抓这样的数据,需要找到XHR的URL,这样的URL一般包括token,一段时间后就失效,因此需要动态抓取网页发起的请求。
PowerBI运行Python脚本抓取网页,如果碰到动态网页的情况,可以使用PlayWright监控网页发起的request,找到需要的request后,处理相应response数据,返回PowerBI。
环境
安装conda,再安装playwright、pandas、numpy、matplotlib等包
其中pandas、matplotlib是必装的,因为PowerBI做了一个wrapper,import了os、pandas和matplotlib。安装pandas附带安装了numpy。
playwright是这次要用的包。
1 | conda create -n excel pandas matplotlib playwright |
PowerBI设置中配置好python的主目录。如果用虚拟环境,就配置虚拟环境的主目录。
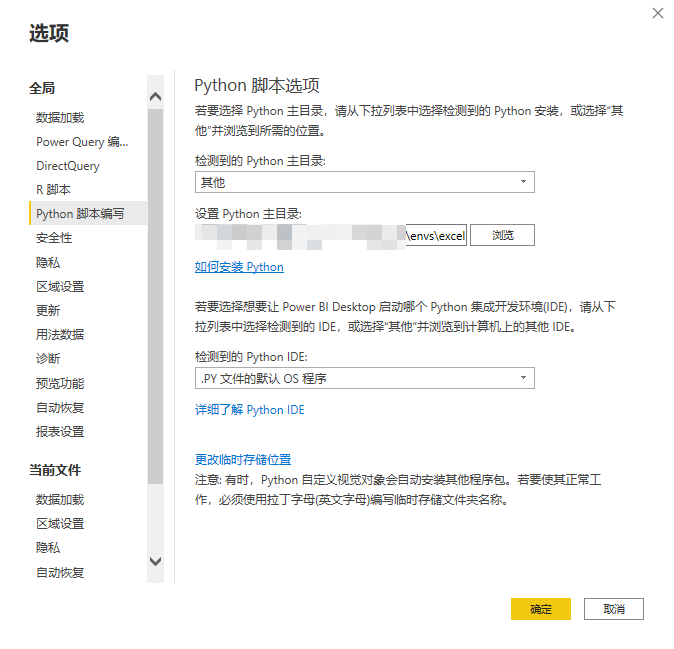
解决NUMPY报错
引入Python虚拟环境时,低版本(1.22版本以前)numpy,import的时候会报找不到dll的错误。
1 | ***\envs\excel\python.exe -c "import numpy" |
安装1.22以后版本的numpy能解决问题。
如果一定要使用低版本的numpy,则可以拷贝所有的mkl_*.dll到numpy目录
1 | copy ***\envs\excel\Library\bin\mkl_*.dll ***envs\excel\Lib\site-packages\numpy\core |
脚本
在PowerQuery中新建一个查询,数据源选Python。
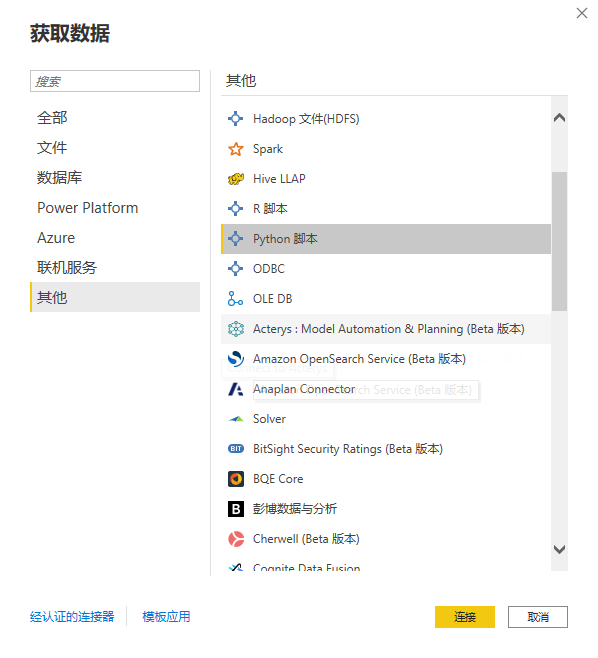
在弹出的对话框中输入Python脚本。
1 |
|
代码还是比较简单,基本上和PlayWright教程差不多。
要注意一点,page.on的回调函数response有时间限制,解析response.json()这样的操作都有可能超时。
可以先将response取出来,page.goto全部完成之后,再处理response的数据,并赋值给df,返回PowerQuery。